详解PCRE正则匹配的引擎、回溯、贪婪问题
详解PCRE正则匹配的引擎、回溯、贪婪问题

前言:
本篇文章字数较多,并且有大量篇幅讲解正则匹配的过程,如果有疏忽(字母标错),请多多海涵~
本文重点研究PCRE的正则匹配,并且使用PHP代码进行相关阐述。
正则匹配的两种引擎:
对于人来说,想要比较一个字符串是否满足某一个条件,通常是对字符串和条件反复比较,这其中并没有一定的规则,通常随着人的心情波动。而对于正则匹配,其存在的意义同样也是比较一个字符串是否满足某一个条件,但是对于机器语言来说,必须满足一定的规则,不能模棱两可。
因此在比较字符串是否满足某一条件时,就存在两种比较方法:NFA(确定型有穷自动机)、DFA(不确定型有穷自动机)。说白了就是:以正则表达式主导还是以字符串主导
NFA
首先对于PHP语言来说,正则匹配往往采用的是PCRE的模式,而PCRE采用的正是NFA的引擎。对于NFA来说,通俗的讲就是以正则表达式主导。接下来就给出一个正则表达式以及一个待匹配字符串进行阐述。
text = 'after tonight'
regex = 'to(nite|nighta|night)'
对于NFA来说,以正则表达式主导,也就是拿着正则表达式去比较待匹配字符串。匹配的过程如下:
- 最开始,正则拿出
t字符与待匹配字符串中的a进行匹配,匹配失败 - 然后同理匹配
f也失败,直到匹配到f后面的t字符 - 这个时候正则会拿出第二个字符
o进行匹配,然而o与e字符不一样,匹配失败,这个时候正则表达式回溯到第一个字符t - 因为上方匹配失败,接下去匹配下一个
t字符,直到匹配到空格后面的t字符 - 同理,这个时候正则拿出第二个字符
o进行匹配,发现与上一步匹配到的o字符一样,匹配成功 - 接着匹配后面三个待匹配字符,依次类推
通过这一个示例,我们大概可以从中理解NFA引擎是怎么个运作方式了。
接下来我们研究DFA匹配引擎。
DFA
对于DFA引擎来说,就是以字符串主导的匹配模式,接下来还是用上方的这一个例子来描述DFA引擎的匹配过程是怎么样的。
text = 'after tonight'
regex = 'to(nite|nighta|night)'
同样的还是这一个例子,对于DFA引擎,匹配过程如下:
- 最开始,待匹配字符串拿出第一个字符
a来与正则的第一个字符t匹配,匹配失败 - 匹配失败后,待匹配字符串拿出第二个字符
f与正则的第一个字符t匹配,匹配失败 - 匹配失败后,待匹配字符串拿出第三个字符
t与正则的第一个字符t匹配,匹配成功 - 此时待匹配字符串拿出第四个字符
e与正则的第二个字符o进行匹配,匹配失败,正则回溯到t - 同理,直到待匹配字符串拿出空格后面的
t字符匹配时,才匹配成功 - 同理
o也匹配成功 - 匹配成功后待匹配字符串就会拿出
n与正则中的三项可选匹配进行并行匹配 - 以此类推
同样通过这一个示例,也大致能了解DFA引擎的运作方式。
接下来分析NFA与DFA这两者的异同。
异同
异
很明显,NFA引擎是以正则表达式主导,DFA引擎是以字符串主导,这其实就是这两者最大的不同点。对于初学正则表达式的人来说(我也是),往往不会在乎他们的引擎到底是什么,差距在哪,通常都会用人最通常的思维去衡量正则表达式,也就是说能匹配到就好了,能满足业务逻辑即可,但是对于程序来说,必须要给它指明一个方向,到底以什么参数主导,必须选一个,不能不选,也不能都选。(上升到哲学问题了。
除此之外,还有一个不同点就是:NFA引擎对于待匹配字符串中的某个字符可能会产生多次匹配,而DFA引擎对于待匹配字符串只会遍历一次。因此DFA的匹配与正则表达式无关,而NFA的匹配与正则表达式有关。
同
相比找不同,往往人们并不会关注相同点,而这片文章后续要研究的正则匹配回溯问题,其实这个问题就出现在人们会忽略的正则表达式回溯问题上。
可以看到,无论是哪一种引擎,对于正则表达式而言,都会产生回溯,而在数据结构中,产生回溯其实是一件很危险的事,因为如果产生的回溯过多,就会造成栈溢出,爆栈等等,造成业务系统卡顿。因此接下来的篇幅就会着重探讨回溯的问题。
回溯:
虽然前面的示例中已经出现了回溯问题,但是不够明显,不够直观。因此这里再用一个示例来看一下回溯的过程。
假设我们这个时候有一个正则表达式如下:
ab{1,3}c
很明显,上方的正则表达式是需要匹配abc,其中b可以出现1-3次
情况1
当我们的待匹配字符串为abbbc时,很正常,全程一次就匹配成功,没有产生回溯。
情况2
当我们的待匹配字符串为abc时,我们来看看这一个匹配过程是怎样的:
| 正则表达式 | 待匹配字符串 | 备注 | |
|---|---|---|---|
| 1 | a | a | |
| 2 | ab | ab | |
| 3 | ab{1,3}b | abc | 匹配不成功,回溯 |
| 4 | ab{1,3} | ab | |
| 5 | ab{1,3}c | abc |
可以看到,在第三步的时候出现了回溯。
但是这个时候,就会有个问题,既然第2步已经匹配到了一个b,为啥这个正则表达式这么贪心,匹配一个就够了呀,直接匹配c不就好了,还想着去匹配第2个b,不匹配第2个b不就不回溯了嘛。
这个问题就涉及到正则表达式匹配的贪婪模式以及非贪婪模式
贪婪模式与非贪婪模式:
对于PCRE,其中有4个比较常用的元字符:
-
*匹配前面的子表达式零次或多次 -
+匹配前面的子表达式一次或多次 -
?匹配前面的子表达式零次或一次 -
{n,m}匹配前面的子表达式n-m次,{n,}匹配前面的子表达式至少n次,{n}匹配前面的子表达式n次
贪婪模式
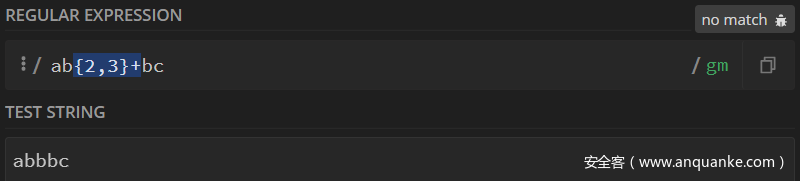
对于待匹配字符串abbbc,有如下正则表达式:
/ab{2,3}+bc/
整一个匹配过程如下:
| 正则表达式 | 待匹配字符串 | 备注 | |
|---|---|---|---|
| 1 | a | a | |
| 2 | ab{2,3}+ | ab | |
| 3 | ab{2,3}+ | abb | 贪婪模式继续匹配 |
| 4 | ab{2,3}+ | abbb | 贪婪模式继续匹配 |
| 5 | ab{2,3}+b | abbbc | 正则需要b,但是待匹配字符串没有b,匹配结束 |
可以看到,整一个过程中因为是贪婪模式,所以正则表达式第1个b就已经把待匹配字符串中的3个b吞掉了,而正则表达式第2个b就没得匹配了,所以在这个匹配过程中,匹配不到任何字符。
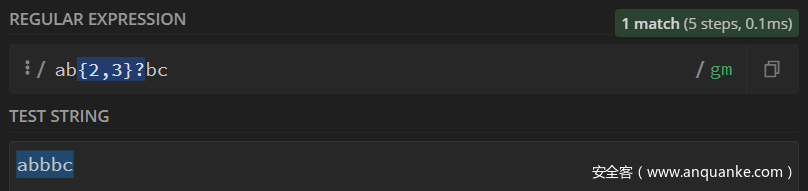
非贪婪模式
同样的还是一样的字符串abbbc,但是不一样的正则表达式。
/ab{2,3}?bc/
| 正则表达式 | 待匹配字符串 | 备注 | |
|---|---|---|---|
| 1 | a | a | |
| 2 | ab{2,3}? | ab | |
| 3 | ab{2,3}? | abb | 匹配了两个b,非贪婪,见好就收,下面不匹配 |
| 4 | ab{2,3}?b | abbb | 成功匹配b |
| 5 | ab{2,3}?bc | abbbc | 成功匹配整个字符串 |
在非贪婪模式下,成功匹配整个字符串,在正则表达式测试网站上结果如下:
贪婪、回溯问题引发的漏洞:
上面的篇幅主要探讨了两个方面的东西:贪婪、回溯。试想一下,如果将这两者结合在一起是否会产生漏洞。
首先,在PHP中,对正则表达式回溯问题有做防备,在php.ini中有下方两个设置:
pcre.backtrack_limit //最大回溯数
pcre.recursion_limit //最大嵌套数
其中默认情况下,pcre.backtrack_limit的值为100000,那如果我们超过这个值的时候,正则函数会返回什么呢?
问题
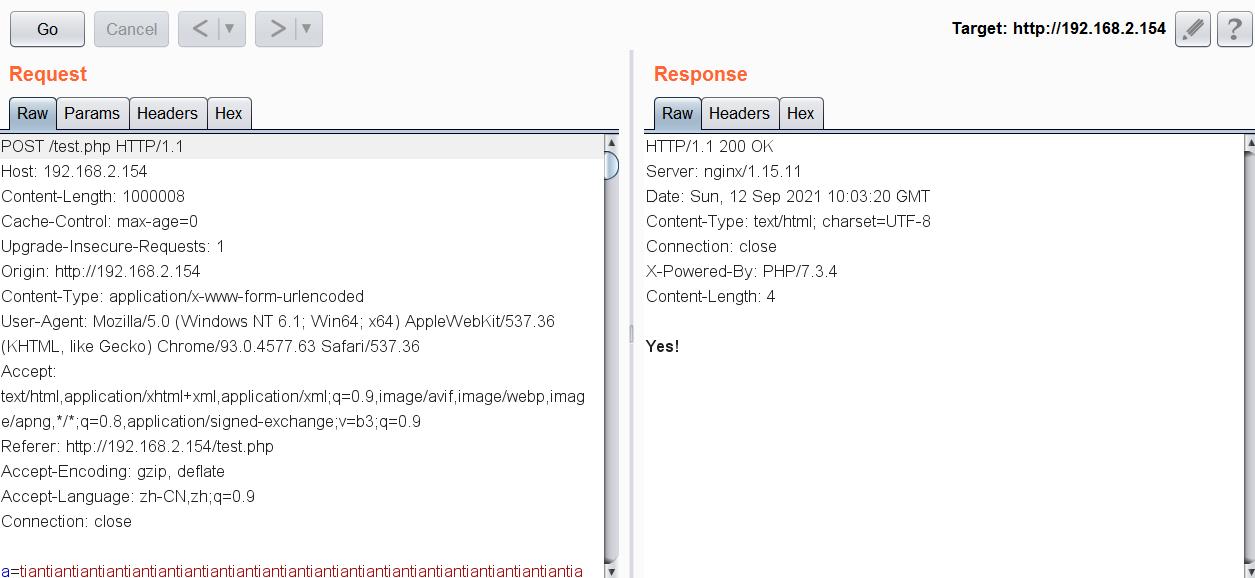
假设我们有以下代码:
<?php
$a = $_POST["a"];
if(preg_match('/.+?Lxxx/i', $a)){
die('no!');
}
if(stripos($a,"ttLxxx")===FALSE){
die("no!!");
}
echo "Yes!";
上方代码正则不允许Lxxx前面有字母,但是又需要字符串中包含ttLxxx。
在这一段代码,如何才能让程序输出Yes?
分析
既然正则不允许,并且正则前面是.+?的非贪婪匹配,所以我们可以添加足够多的字母造成回溯。
假设我们传入ttLxxx,由于是非贪婪匹配,.+?匹配到字符t的时候,并不会很贪心地把字符t拿走,而会留给后面的字符L,但是t没办法匹配L,导致一次回溯,同理,第2个t也会造成回溯,由此可见,只要我们拥有足够多的t,就会造成足够多次的回溯。当回溯达到我们php.ini中的设置时,正则就会返回false
所以我们生成足够多的字符POST传给a
<?php
$a = str_repeat("tian",250000);
$a .= "ttLxxx";
echo $a;
将生成的字符传给a,程序就输出Yes。